
시드니랩
[Information Retrieval] 1. 개요 본문
1. IR 의 간략한 역사
일반인에게는 Search Engine, 학계에서는 Information Retrieval 이라는 용어로 불리는 이 IR은 사실 컴퓨터가 등장하기 훨~씬 이전부터 존재했었다. 그리고 익숙한 Search Engine 이라는 용어는 Information Retrieval이 Web에 구현되고 나서부터 등장했다. 1950년대 이전에는 이 분야는 Computer Scientist 나 Mathematicians 보다 Librarian 에 의해서 더 잘 연구되기도 했던 분야이다. 도서관이야 말로 전통적으로 정보검색이 이루어지는 공간이기 때문이다.
1960년대에는 특정 Search Field에 의존해서 검색을 했었음 예를들어 IBM Stairs 은 title="computer" AND body contains "IBM" 과 같은 Boolean 연산으로 검색을 했다.
1993년 Altavista, InfoSeek 같은 First Generation Search Engine은 Web이 등장함에따라 전통적인 search method를 wed에 더하기도 하였고, Spider/Crawler 을 더하기도 하였다.
그후 등장한 Web Search Engine들에는 Automatic Categorization 등의 Search Feature들이 임베딩 되기도 하였다.
2. IR 의 예시
Google, Naver 같은 검색엔진이 너무나도 유명해져서, Search Engine = Google 을 떠올리기가 쉽상이다. 하지만 Search Engine의 범주는 상당히 넓다. 그 Search Engine들을 간략히 분류해보면 아래와 같이 분류할 수 있다.
☞ 분류 1 : Digital Libraries - 요즘 도서관 홈페이지를 생각하면 된다. 도서관 사이트에는 Federated search 라는, 타 도서관과 연계해 검색해주는 Search가 내장되어 있기도 하다.
☞ 분류 2 : Web search - Google, Naver 같이 Web을 검색해주는 엔진
☞ 분류 3 : Vertical search - 주제가 있는 검색이다. Alibaba, Amazon 같은 e-commerce 검색은, Buy <-> Sell 의 Vertical 구조이다.
그렇기때문에 Data 가 Web Search에 비해 훨씬 Structured 되어 있다. Query자체도 훨씬 간단하다.
✤ Employee record 를 검색하는 것은, IR의 범주에 속하지 않는다. IR의 최종 결과물이 사람이기때문이다.
3. IR이 다루는 데이터
✤ 가장 방대한 Web Search 를 기준으로 생각해볼때, Relational Database 와 다르게, IR이 다루는 데이터는 Unformatted, Unstructured 하다. 예를들어 뉴스기사 같은 텍스트는 가지각각 너무다르기 때문에 IR입장에서는 전혀 구조화 되어있지가 않다.
✤ 또, IR은, Web이 등장함으로써, HTML, XML 같이 어느정도 형식이 갖춰진 파일들도 다룬다. 이렇게 형식이 갖춰진 파일들을 Semi- structured data 라고 한다.
✤ 동영상이나 이미지 같은 Non Textual Data 또한, IR이 다루는 데이터 이기도 하다. (Image Processing 관련 내용)
4. Web Search Engine 의 아키텍처
Web Search Engine 에 대해 좀더 자세히 들여보면 아래와 같다.
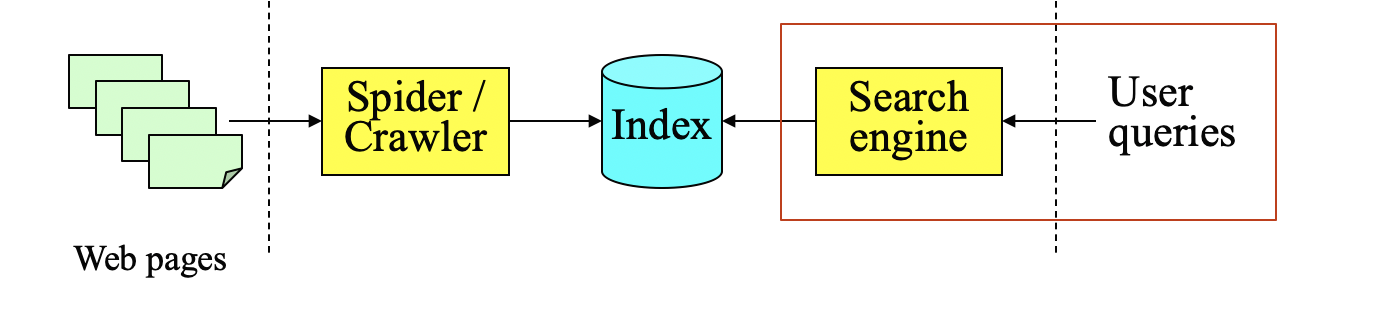
Web Search Engine의 대표인 google로 예를들어 위 그림을 설명해 보자.
✣ How Google Search Works
1단계 Crawling : Google은 새 페이지를 방문할때 마다 Spider을 사용해서 Crawling을 한다. Spider의 동작원리는 발견한 페이지 내부에 있는 링크를 연쇄적으로 접속 하여서 연결된 페이지를 계속 찾아내는 것이다. 이렇게 Google이 이미 방문했던 페이지는 사용자가 검색하면 바로 나올 수 있게 되어있고, Blog 나 Tistory같은 Webhosting 엔진은 업데이트가 발생 시에, Google에게 Crawl 하라고 요청한다.
2단계 Indexing : Google이 새 페이지를 발견한 후, 해당 페이지가 무슨일을 하는 페이지인지 분석한다(HTML <title> Tag 같은 것들 분석). 분석된 페이지는 Index되어서 Google Index 서버에 저장이되는데, 이 Index 서버는 어마어마하게 많은 컴퓨터들이다. Google Server 만 이미지 검색해도 나온다.
3단계 Serving and Ranking : 후에 유저가 Query하면, Google Index Server 에서부터 유저에게 최적의 정보를 제공한다. 그래서 User가 검색을 하면, Web 자체를 검색하는것이 아닌, Google Index를 검색하는 것이다. Google Index에서는 수천대의 컴퓨터에서 Larry Page가 고안해낸 알고리즘으로 Indexing해놓은 Web들을 Ranking한다. 주로, 유저가 Query한 단어들이 얼마나 반복되는지, 어느위치에 있는지, 웹페이지가 스팸은 아닌지 등을 확인해서 순위를 매겨 유저에게 Respond 한다.
➢ Google Server 처럼 분산시스템에서 어려운것은 새로운 정보의 Update이다. Webpage가 업데이트되면 Indexing을 다시해야하는데, 실로 엄청난 시간이 소요될 것임을 짐작할 수 있다.
5. IR이 중요한 이유
산재되어 있는 수많은 데이터들은 정형화 되어있지 않고, Textual Form으로 여기저기 퍼져있다. 회사 내에서도, Structured Database 내의 데이터가 아무리 많다고 하더라도, 공지사항이나 사내게시판에 올라와있는 text들이 훨씬 많다. 뿐만 아니라, World Wide Web 만 보더라도, 정형화 되어있지 않은 데이터들이 얼마나 많은지 새삼 느낄 수 있다.
6. IR이 어려운 이유
- Web 의 크기가 매시간 기하학적으로 커지기때문이다.
- 데이터의 세세한 Semantic(의미)를 알아내기 힘들기 때문이다. 예를들어 "I ate apple" 의 apple이 아이폰 apple인지, 먹는 사과인지 추가적인 작업이 없으면 알아내기 힘들다. 그래서 문장 앞뒤를 분석해야 할 필요가 있는 것이다.
- 세상의 User들은 각자 너무도 다르기 때문에 같은 정보를 검색에 반환해도 User마다 만족도가 다를것이다. 그래서 User experience의 충분한 분석이 필요하다.
- 같은 주제라도, 저명한 과학자가 작성한것과 고등학생이 작성한 Article이 검색엔진에서는 동일하게 바라보게된다. Key word로 접근하기 때문이다.
'랩 > Information Retrieval' 카테고리의 다른 글
| [Information Retrieval] 4. Retrieval model - Vector Space Model 보충 (0) | 2020.09.27 |
|---|---|
| [Information Retrieval] 4. IR 과 NLP (0) | 2020.09.27 |
| [Information Retrieval] 3. Retrieval model - Statistical Model (0) | 2020.09.20 |
| [Information Retrieval] 2. Retrieval model - Boolean Model (0) | 2020.09.20 |



